Project 5: Fun With Diffusion Models!
Contents
- Introduction
- Part 0: Initial Experiments
- Part 1.1: Forward Process
- Part 1.2: Classical Denoising
- Part 1.3: One Step Denoising
- Part 1.4: Iterative Denoising
- Part 1.5: Diffusion Model Sampling
- Part 1.6: Classifier-Free Guidance
- Part 1.7: Image to Image Translation
- Part 1.8: Visual Anagrams
- Part 1.10: Hybrid Images
- Part B: Training Diffusion Models
- Part 2: Time Conditioning
- Part 3: Class Conditioning
In this project I will implement and deploy diffusion models for image generation.
I used the given sample code to produce images in different inference steps with seed 777. I use the same seed in the whole part A.
10 Steps



50 Steps



I used the equation below here to add noise to campanile (given picture). Results below: \[ x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon \quad \text{where} \quad \epsilon \sim \mathcal{N}(0, 1) \]
Original Image

Noisy Images at Different Timesteps



Here we're trying to denoise using gaussian filter blur


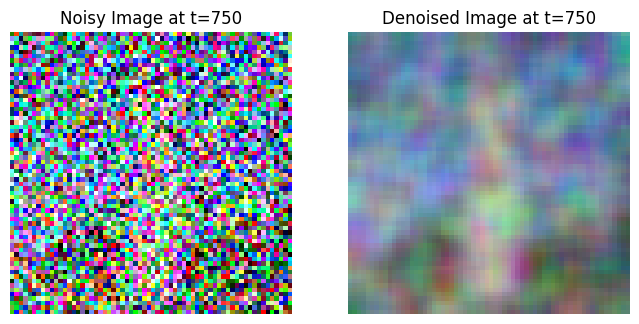
Use the pretrained diffusion model to denoise the image



Tried to get much better result by denoising in steps to get a clear image. \[ x_{t'} = \frac{\sqrt{\bar{\alpha}_{t'} \beta_t}}{1 - \bar{\alpha}_t} x_0 + \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t'})}{1 - \bar{\alpha}_t} x_t + v_\sigma \]
Where:
- \(x_t\) is your image at timestep \(t\)
- \(x_{t'}\) is your noisy image at timestep \(t'\) where \(t' < t\) (less noisy)
- \(\bar{\alpha}_t\) is defined by
alphas_cumprod, as explained above. - \(\alpha_t = \frac{\bar{\alpha}_t}{\bar{\alpha}_{t'}}\)
- \(\beta_t = 1 - \alpha_t\)
- \(x_0\) is our current estimate of the clean image using equation A.2, just like in section 1.3
Denoising Results






Did the same thing as in 1.4 but with random noise, results below:





Computed both conditional and unconditional noise estimate, used this \[ \epsilon = \epsilon_u + \gamma (\epsilon_c - \epsilon_u) \] to get better results:

Take an image, add noise to it and then denoise it to get a bit different image :)
Starting Image

Custom Translations


Hand Drawn and Web Images
Let's start with custom, original first, and then epochs
Avatar Original
Avatar Progression
First Doodle

First Doodle Progression






Second Doodle
Second Doodle Progression






Inpainting
In this part we use a mask to apply a process to specific location of the image.
Campanile Example



Campanile Result

Panda Example



Panda Result

Sunflower Example



Sunflower Result

Text-Conditional Image-to-Image Translation
Use a prompt to translate an image. The next one is rocket prompt on campanile
Campanile to Rocket Progression






Rocket to Panda Progression






Rocket Prompt on Sunflower






This part the main idea is making different optical models. The first one is an image that looks like one thing when shown correctly, and shows a complete different thing when flipped. To do this, we denoise an image with two prompts(one upside down) at every step to get noise est., and then flip the flipped denoised image back and add it to the first one. To make more sense, here's the equation: \[\epsilon_1 = \text{UNet}(x_t, t, p_1) \] \[\epsilon_2 = \text{flip}(\text{UNet}(\text{flip}(x_t), t, p_2)) \] \[ \epsilon = (\epsilon_1 + \epsilon_2) / 2 \] The first visual illusion is an oil painting of old man x an oil painting of people around campfire

Old Man (Upright)

Campfire (Flipped)
The second one is pen x rocket, which, I initially thought was a good mix. After a few runs, I realized it is not a good choice.

Pen

Rocket
The third one is a man and a dog mix:

Man

Dog
Hybrid images of my assignment is an illusion with distance, the first one is supposed to be a lithograph of waterfall to a lithograph of a skull, done like this: \[ \epsilon_1 = \text{UNet}(x_t, t, p_1) \] \[ \epsilon_2 = \text{UNet}(x_t, t, p_2) \] \[ \epsilon = f_\text{lowpass}(\epsilon_1) + f_\text{highpass}(\epsilon_2) \] Below are three of my tries on prompts: "waterfall" + "skull", "pen" + "skull", "amalfi cost" + "campfire"



In this part we implement, UNet, use it to train a denoiser, and then try to add time and class condition. Some info on UNet below:
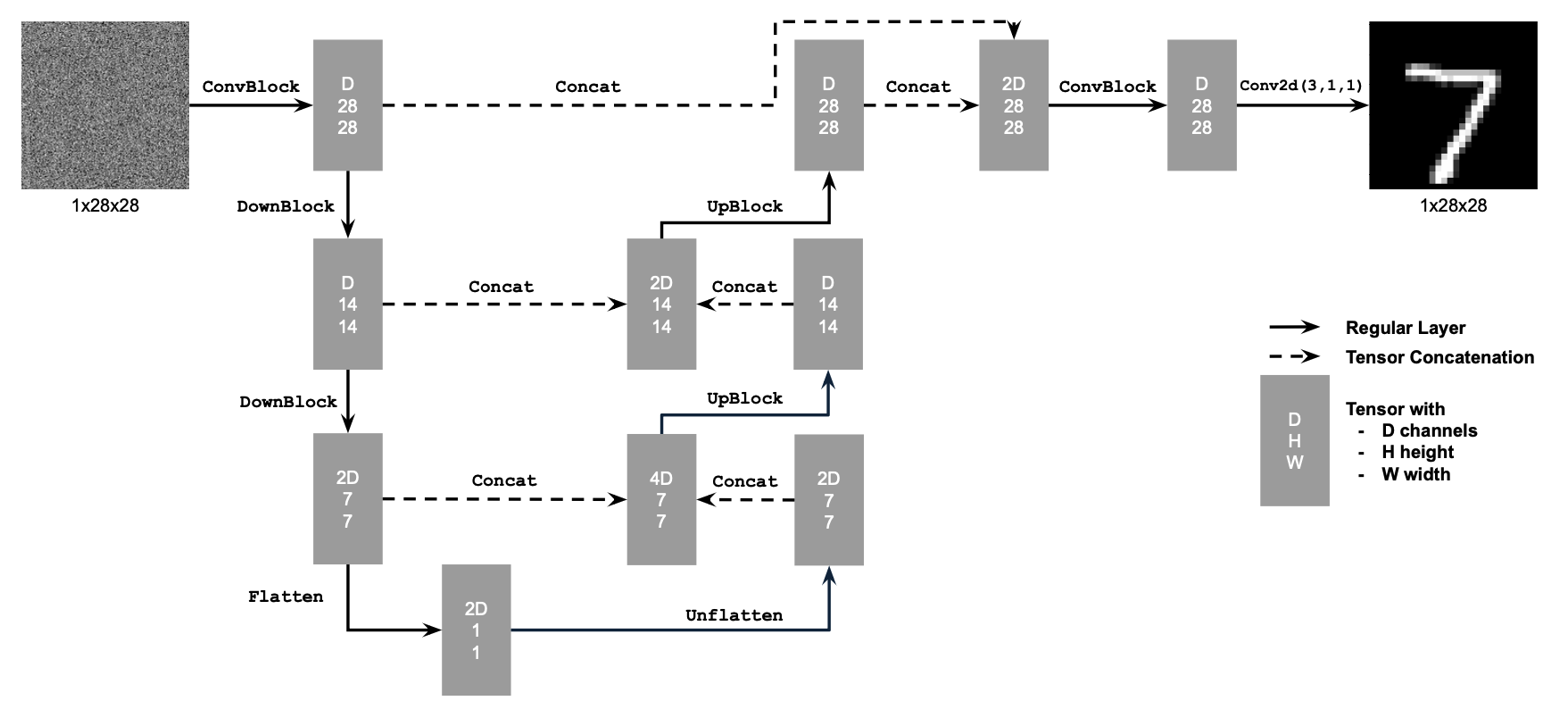
Unconditional Architecture
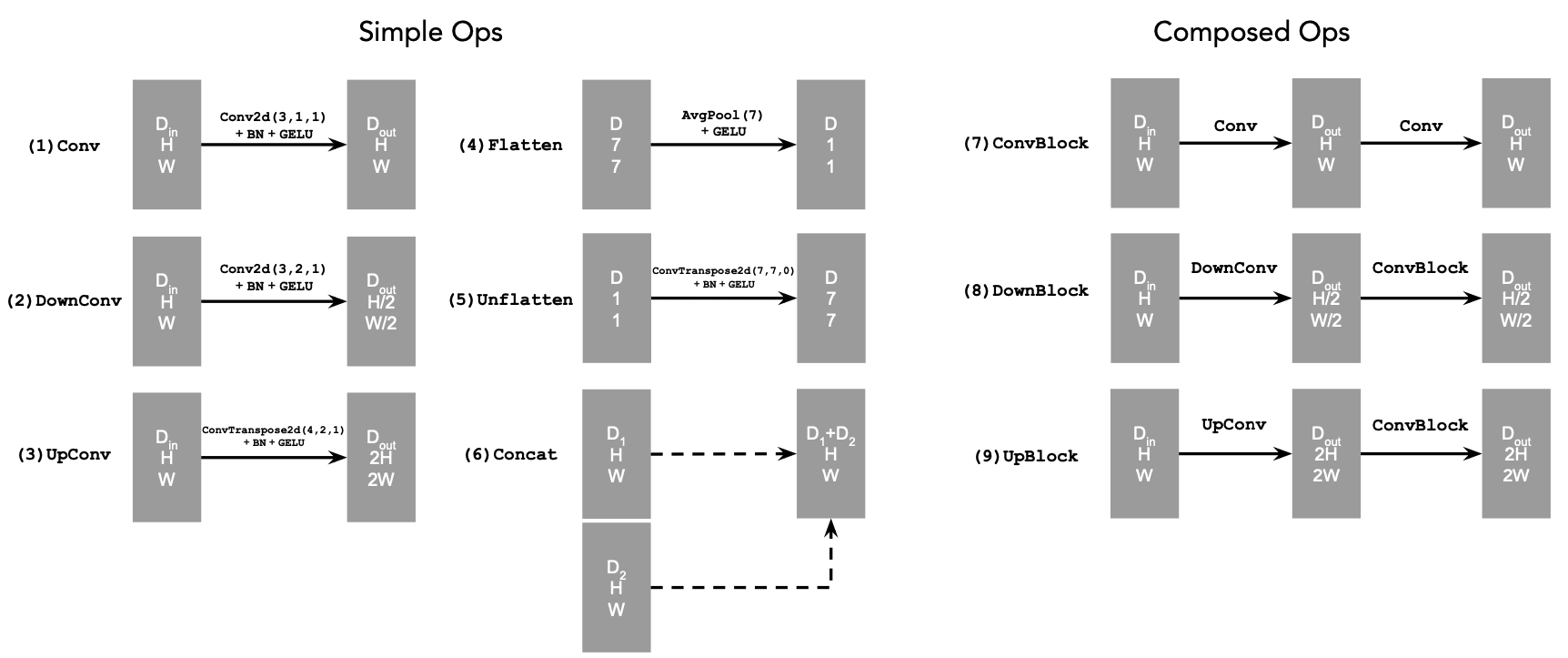
Atomic Operations
This is what uncond UNet looks like. First, we implement noise algorithm though. Here's what the process looks like with different sigma values:

Then we train our uncond UNet on sigma=0.5, and here are the results after the first and fifth(last) epoch:
Epoch 1 Results

Epoch 5 Results

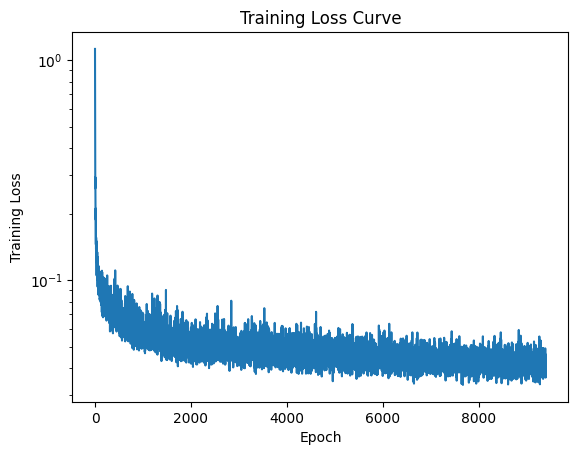
Training Loss Curve
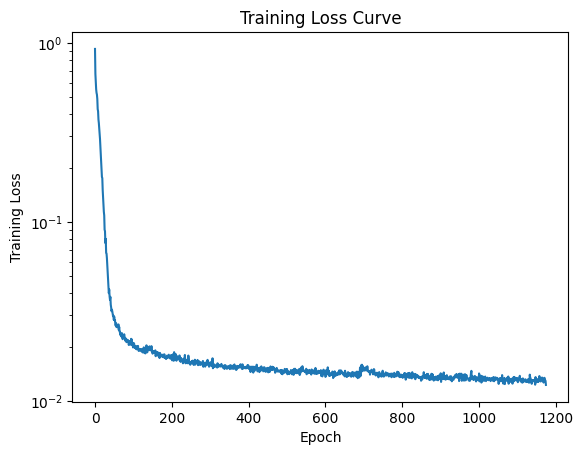
I tried to use my trained model on different sigma values, and this is what I got:

Here I added my time conditioning to UNet, here's the diagram for more understanding
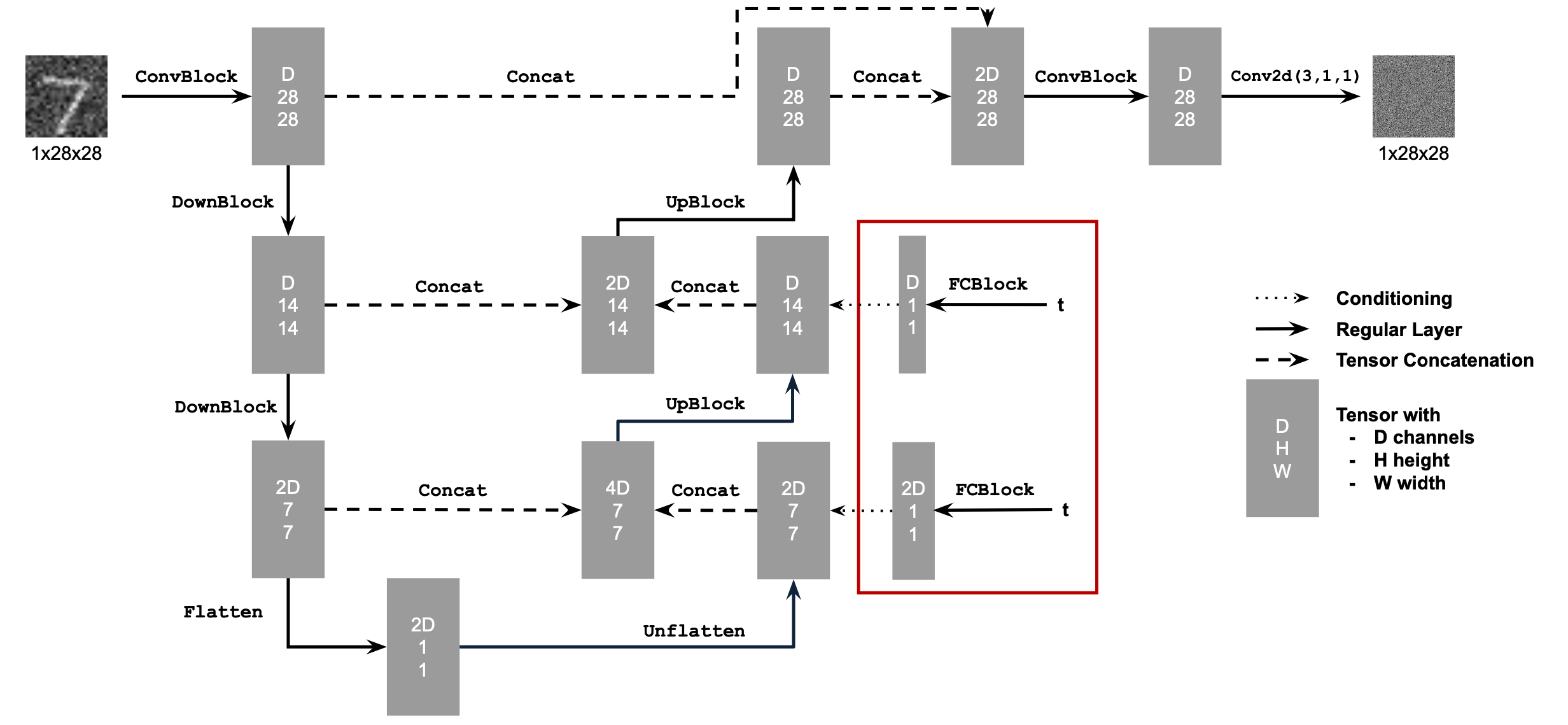
Conditional Architecture
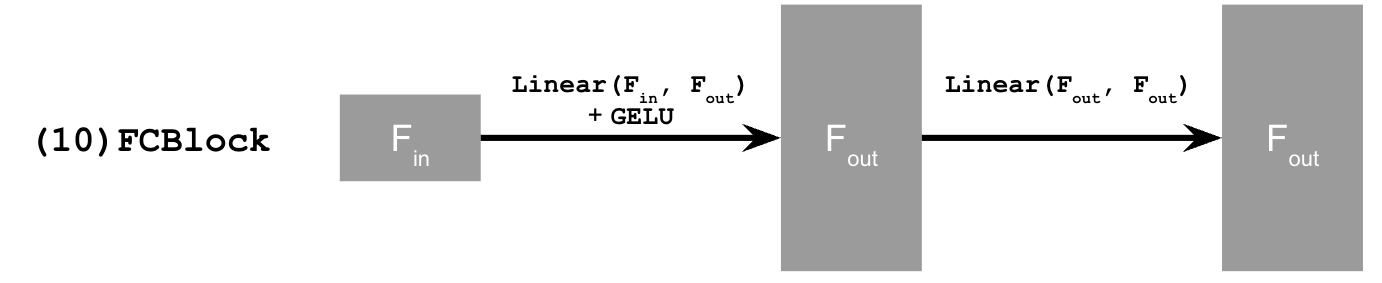
Fully Connected Layer
Results After Epoch 5

Results After Epoch 20

Training Loss Curve